

데이터 분석 혹은 지도학습 모델을 학습하기 위해서는 반드시 하나의 통합된 데이터셋이 필요합니다. 많은 경우 데이터는 두 개 이상으로 나뉘어져 있고 이들을 병합해야하는 전처리를 수행해야합니다.
센서, 로그, 거래 데이터 등과 같이 크기가 매우 큰 데이터는 시간과 ID 등에 따라 분할되어 저장되어 있습니다.
통합해야하는 데이터가 많은 경우 빈 데이터 프레임을 생성하는데 반복문을 사용하여 불러온 데이터를 함수를 이용하면 효율적으로 통합할 수 있습니다.
오늘은 데이터를 병합하는 방법에 대해서 R과 python 명령어를 비교해보도록 하겠습니다.
1. R코드
예제로 사용할 데이터프레임을 생성해보겠습니다.
CLASS <- c('C1', 'C2', 'C3', 'C2', 'C4')
COUNTRY <- c('KR', 'DE', 'DK', 'KR', 'DE')
SCORE <- c(7,6,4,5,2)
df1 <- data.frame(CLASS, COUNTRY, SCORE)
CLASS <- c('C1', 'C2','C3', 'C5', 'C6')
COUNTRY <- c('US', 'DK', 'JP', 'KR', 'KR')
SCORE <- c(8,9,5,2,8)
df2 <- data.frame(CLASS, COUNTRY, SCORE)1) rbind()
두 데이터프레임을 세로로(위+아래) 붙일 경우 rbind 함수를 사용합니다. rbind는 row bind의 약자입니다. 이때 두 데이터프레임의 열의 갯수와 속성, 이름이 같아야 하고 다른 경우 에러가 발생합니다.
rbind(df1, df2)
2) cbind()
cbind는 열 결합으로(왼쪽+오른쪽)으로 붙일 경우 사용합니다. 이때 서로 결합하려고 하는 두 데이터프레임의 행의 갯수가 서로 동일해야하고 그렇지 않다면 에러메세지가 발생합니다.
cbind(df1, df2)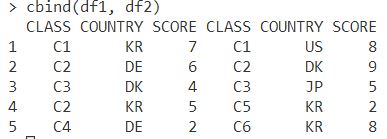
3) merge()
두 데이터프레임을 열 결합할 때 동일 key값을 기준으로 결합 해야할 경우가 있을 것 입니다. cbind의 경우 각 행의 관찰치가 서로 동일 대상일 때 그리고 갯수가 같을 때만 가능한데 만약 그렇지 않은 경우라면 cbind를 사용할 수 없을 것입니다. 이때 merge를 사용해줍니다. sql의 join처럼 merge도 어느 쪽에 기준을 두고 데이터를 결합하느냐에 따라 종류가 나뉘게 됩니다.

(출처 : rfriend 블로그)
4) dplyr()
dply 패키지는 두 테이블 간 join이 sql의 join을 차용해서 만들어졌기 때문에 sql을 아는 분들은 매우 쉽게 느껴지실 겁니다. dplyr 패키지가 두 테이블 join을 하는데 제공하는 함수는 inner_join, left_join, right_join, full_join, semi_join, anti_join, nest_join 총 7개이며 크게 Mutating joins, Filtering joins, Nesting joins의 3개의 범주로 분류할 수 있습니다.
제공되는 함수에 대해서 이해하기 쉽게 도식화된 자료가 있어서 가져왔습니다.

(출처 : rfriend 블로그)
1-1) Mutating joins
Mutating joins는 일반적으로 sql join 형태의 inner, left, right, full join입니다. 어느쪽 테이블이 기준이 되느냐에 따라 사용하는 함수가 달라집니다. join에 사용하는 함수들의 기본 구문은 아래와 같이 왼쪽테이블, 오른쪽테이블, 두 테이블을 매칭하는 기준 컬럼, 복사여부, 인덱스 등의 매개변수로 구성되어 있습니다.
inner_join(df1, df2, by = 'CLASS', copy = FALSE, suffix = c(".df1", ".df2"))
left_join(df1, df2, by = 'CLASS', copy = FALSE, suffix = c(".df1", ".df2"))
right_join(df1, df2, by = 'CLASS', copy = FALSE, suffix = c(".df1", ".df2"))
full_join(df1, df2, by = 'CLASS', copy = FALSE, suffix = c(".df1", ".df2"))
만약 서로 다른 key 컬럼을 갖고 있을 경우 by 매개변수에 서로 다른 변수 이름을 구체적으로 명시해주면 됩니다.
by = c("왼쪽테이블key명" = "오른쪽테이블key명")
1-2) Filtering joins
두 테이블의 매칭이 되는 값을 기준으로 한쪽 테이블의 값을 걸러내는데 사용합니다. semi join은 왼쪽 테이블에서 비교하는 오른쪽 테이블의 값을 제외하고 가져옵니다. 오른쪽 테이블과 중복되는 값을 필터링하는 하는 것이죠.
anti join은 왼쪽 테이블에서 비교하는 오른쪽 테이블의 값과 중복되는 값을 뺀 나머지 값을 필터링하는데 사용됩니다. filtering join에서 오른쪽 테이블은 비교대상으로만 사용되고 값을 가져오지는 않습니다.
semi_join(df1, df2)
anti_join(df1, df2)
1-3) Nesting joins
nest join은 왼쪽 테이블의 모든 행과 열을 가져오고 오른쪽의 매칭되는 부분의 컬럼 값들을 list 형태로 중첩되게 묶어서 결합합니다. 즉, 오른쪽 테이블에 여러 컬럼들이 있더라도 1개의 컬럼에 list 형태로 묶여서 join이 됩니다.
2. Python 코드
R에서 사용한 예제를 그대로 python에서도 사용해보도록 하겠습니다.
import os
import pandas as pd
df1 = pd.DataFrame({'CLASS':['C1', 'C2', 'C3', 'C2', 'C4'],
'COUNTRY': ['KR', 'DE', 'DK', 'KR', 'DE'],
'SCORE':[7,6,4,5,2]})
df2 = pd.DataFrame({'CLASS':['C1', 'C2','C3', 'C5', 'C6'],
'COUNTRY': ['US', 'DK', 'JP', 'KR', 'KR'],
'SCORE': [8,9,5,2,8]})1) concat()
둘 이상의 데이터 프레임을 이어 붙이는데 사용하는 함수로 DataFrame을 요소로 하는 리스트 입력 순서대로 병합하게 됩니다. axis는 default 0으로 행 단위로 병합을 수행하며 R의 rbind의 기능을 하고, 1이면 열 단위로 병합을 수행하며 R의 cbind 역할을 합니다.
1-1) 행 병합
pd.concat([df1, df2])
concat은 데이터프레임에 라벨링할 수 있는 옵션이 있는데 keys 인수를 이용하여 해당 데이터가 어떤 데이터프레임였는지 알아볼 수 있게 라벨링하는 옵션을 제공합니다.
pd.concat([df1, df2], keys = ['df1', 'df2'])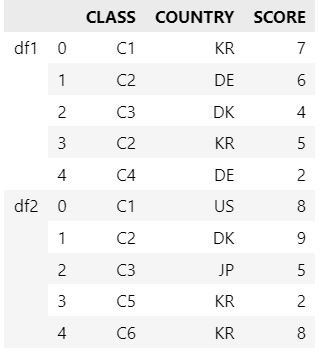
1-2) 새로운 인덱스
ignore_index는 인덱스를 부여하는 방법을 정하며 default는 False라 기존 인덱스를 사용하여 데이터 프레임을 병합힙니다.
pd.concat([df1, df2], ignore_index=True)
1-2) 열 병합
열 병합을 하면 동일한 feature 이름으로 중복되는 feature가 생기게 되고, df1, df2 각 데이터 프레임의 길이가 다른 경우 가장 긴 데이터 프레임에 맞춰서 빈 셀은 NaN 값으로 채워집니다.
pd.concat([df1, df2], axis=1)
Tip. Axis 키워드
axis 키워드는 numpy 및 pandas의 많은 함수에 사용되는 키워드로 연산 등을 수행할 때 축의 방향을 결정하는 역할을 합니다. axis 0이면 행을 1이면 열을 나타내지만 이렇게만 기억하면 논리적으로 이상한 점이 존재하게 됩니다.

axis 키워드는 그 함수의 결과 구조가 벡터 형태(1차원)인지, 행렬 형태(2차원)인지에 따라 그 역할이 조금씩 다릅니다.

2) merge()
효율적인 데이터 베이스 관리를 위해 잘 정제된 데이터일지라도 데이터가 Key 변수를 기준으로 나뉘어 저장되는 경우가 매우 흔합니다. Sql에서는 join을 이용하여 해결하며, python에서는 merge를 이용하여 해결합니다. 일반적으로 사용하는 경우는 어렵지 않지만 다양한 케이스가 존재할 수 있으므로 반드시 핵심을 기억 해야합니다.
(1) 어느 컬럼이 key 변수 역할을 할 수 있는지 확인하고, key 변수를 통일해야합니다.
(2) 레코드 단위를 명확히 해야합니다.
2개의 데이터프레임에 key 변수를 'CLASS' 기반으로 합쳐져 단일 데이터프레임이 된 것을 볼 수 있습니다.
위의 concat() 함수와는 달리 동일한 변수명인 경우 좌측 데이터프레임에는 _x, 우측 데이터프레임에는 _y가 붙은 것을 알 수 있습니다.
pd.merge(df1, df2, on='CLASS')
데이터프레임의 변수명에 임의로 붙여지는 _x, _y가 아닌 다른 이름으로 지정하고 싶다면 suffixes 인수를 사용하여 변경할 수 있습니다.
pd.merge(df1, df2, on='CLASS', suffixes=('_left', '_right'))
만약 합칠 데이터프레임의 key 변수의 이름이 서로 다른 이름을 가지고 있다면 좌측 데이터프레임은 left_on, 우측 데이터프레임은 right_on 인수에 지정해서 다음과 같이 합칠 수 있습니다.
pd.merge(df1, df2, left_on = 'CLASS', right_on = 'CLASS')

merge를 사용하여 단일 데이터프레임을 만드는 경우 조건에 따라 다양하게 join할 수 있습니다.
2-1) outer join
양쪽 데이터프레임의 모든 레코드를 가지게 되며 없는 값에 대해서는 NaN을 채워넣습니다.
pd.merge(df1, df2, on='CLASS', how = 'outer')
2-2) inner join
양쪽 데이터프레임에 공통되는 레코드만 사용하여 생성합니다.

2-3) left join
우측 데이터프레임의 전체 레코드와 이와 매칭되는 좌측 데이터프레임을 보여줍니다. 만약 매칭되는 부분이 없다면 좌측 데이터프레임의 값은 NaN의 값을 포함하게 됩니다.
pd.merge(df1, df2, on='CLASS', how = 'left')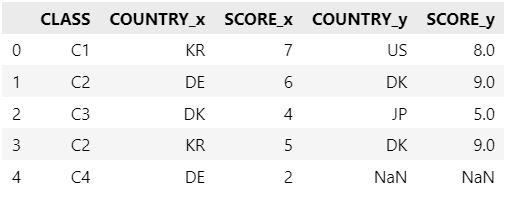
2-4) right join
마찬가지로 좌측 데이터프레임의 모든 레코드와 이와 매칭되는 우측 데이터프레임의 레코드를 가져옵니다. 매칭되는 부분이 없으면 우측 데이터프레임의 값에 NaN을 포함합니다.
pd.merge(df1, df2, on='CLASS', how = 'right')
2-5) index join
데이터 프레임의 컬럼 기준이 아닌 index를 기준으로 합치는 경우 left_index와 right_index를 True로 지정하여 합칠 수 있습니다.
pd.merge(df1, df2, left_index=True, right_index=True)2-6) time-series join
위의 join 방식은 key 값이 완전히 일치하는 경우만 데이터를 합칩니다. pandas는 시계열 데이터프레임을 합칠 수 있는 특별한 함수를 제공하는데 merge_asof()를 사용하게 되면 가장 근접한 키를 기반으로 데이터를 합쳐줍니다. df3과 df4를 합칠 때 df3의 time 변수를 기준으로 잡고, 'nm' 변수를 그룹화하여 병합됩니다.
df3 = pd.DataFrame({'time':pd.to_datetime(['20220524 13:30:00.021',
'20220524 13:30:05.021',
'20220524 13:30:10.021',
'20220524 13:30:15.021']),
'nm':['M', 'G', 'G', 'A'],
'price':[500, 550, 700, 620]})
df4 = pd.DataFrame({'time':pd.to_datetime(['20220524 13:30:00.021',
'20220524 13:30:00.021',
'20220524 13:30:03.021',
'20220524 13:30:04.021',
'20220524 13:30:14.021',
'20220524 13:30:16.021']),
'nm':['M','G', 'M', 'G', 'A', 'A'],
'price':[500,700, 540, 680, 620, 660]})
pd.merge_asof(df3, df4, on = 'time', by = 'nm')
위의 결과를 보면 df3 데이터프레임의 time과 nm으로 groupby한 결과에 df3의 time 보다 작으면서 가까운 시간의 값을 df4에서 가져와 붙인 것을 알 수 있습니다.
또한 merge_asof() 함수 옵션으로 시간 범위 제한을 두어 해당 범위 내에 있는 가까운 시간의 레코드를 가져올 수 있는 기능이 있습니다.
pd.merge_asof(df3, df4, on = 'time', by = 'nm',tolerance=pd.Timedelta('3s'))
감사합니다 :)
참고자료
'머신러닝&딥러닝 > Python' 카테고리의 다른 글
| [패턴] Timeseries 데이터에서 유사한 패턴 index 찾기 (0) | 2022.08.11 |
|---|---|
| [scikit-learn] 다항회귀 PolynomialFeatures (0) | 2022.08.01 |
| [scikit-learn] PCA 기능 (0) | 2022.05.18 |
| [Jupyter notebook] 아나콘다 가상 환경 생성 및 활용 (0) | 2022.05.10 |
| [matplotlib] Line chart 기본 옵션 (0) | 2022.04.22 |
